

目录
- 看PPT
Leftest Heap VS Skew Heap
定义
左偏堆
先来看左偏堆对dist的定义:
一个左偏堆的结点维护了左右子堆的地址、自身的键值、和一个“距离(dist)”。
struct LeftistHeapNode {
ElementType val;
int dist;
LeftistHeapNode * ls, * rs;
};
一共定义了四个”部件“,不难类比到,左偏堆对dist的维护相当于AVL Tree对height的维护,左偏堆->斜堆,可以类比为 AVL ->splay,是一种对维护信息负担的化简。 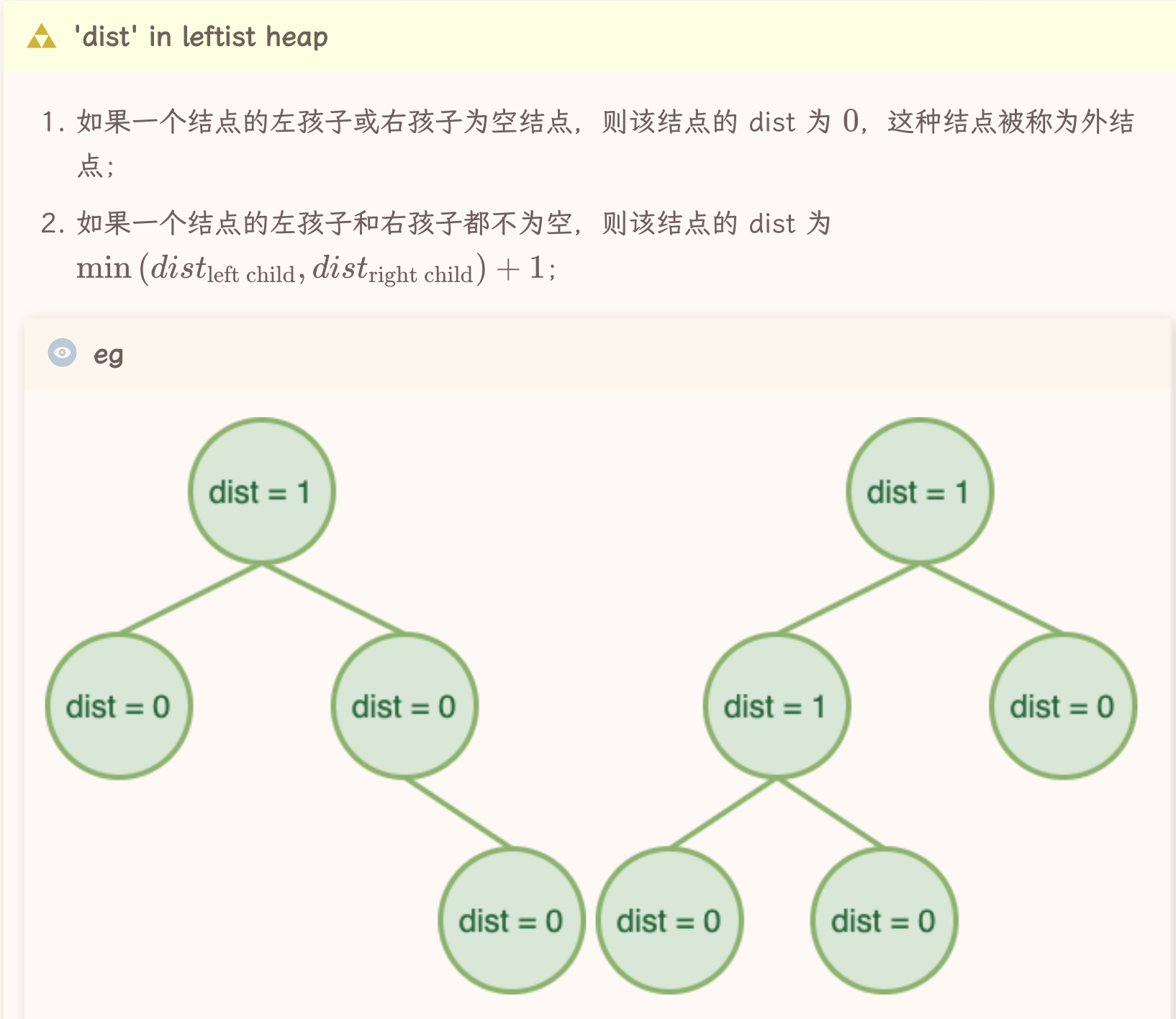 从第二点可以看出,dist是递归定义的。
从第二点可以看出,dist是递归定义的。
从dist定义左偏堆: 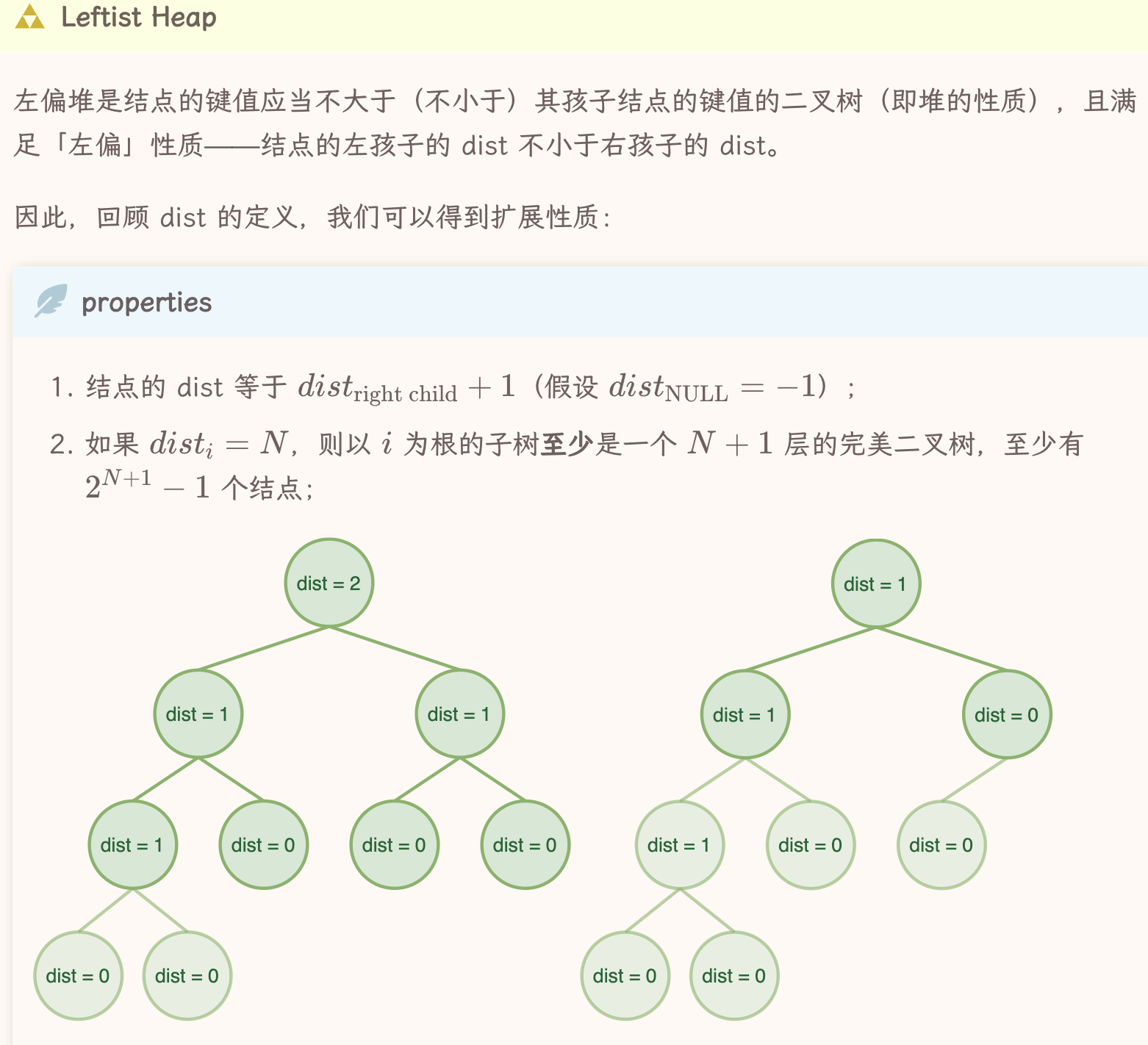
斜堆
再来看斜堆的定义特点。
斜堆只定义了val,*rchild,*lchild,相比左偏堆少了对dist的维护。
斜堆的好处是能够快速合并,实现完全自上而下的并发操作。
下面讲merge操作:
操作:合并
左偏堆
先维护堆的性质,在回溯时维护左偏性质。
即先自上而下按照根的大小合并(根节点和左子树),再自下而上maintain(维护左偏性质,进行左右子树交换)
形式也分为两种方式:递归式和迭代式。迭代式需要额外维护两个指针,分别指向两棵树还没被合并 的子树的根,并不断选择较小的那个合并进去,直到两个指针都为空。
递归式代码:
LeftistHeapNode * merge(LeftistHeapNode * x, LeftistHeapNode * y) {
if (x == NULL) return y;
if (y == NULL) return x;
if (x->val > y->val) {
swap(x, y);
}//小根堆
x->rs = merge(x->rs, y);//自上而下合并
if (x->ls->dist == NULL || x->ls->dist < x->rs->dist) {
swap(x->ls, x->rs);
}//维护交换根节点
x->dist = x->rs->dist + 1;
return x;
}
迭代式代码:
LeftistHeapNode * merge(LeftistHeapNode * x, LeftistHeapNode * y) {
LeftistHeapNode * tx = x, * ty = y;
LeftistHeapNode * res = NULL, * cur = NULL;
while (tx != NULL && ty != NULL) {
if (tx->val > ty->val) {
swap(tx, ty);
}
if (res == NULL) {//res保留返回的根节点
res = tx;
cur = tx;
} else {
cur->rs = tx;
cur = cur->rs;//合并
}
tx = tx->rs;//递归
}
while (ty != NULL) {
if (res == NULL) {
res = ty;
cur = ty;
} else {
cur->rs = ty;
cur = cur->rs;
}
ty = ty->rs;
}
res = adjust(res);
return res;
}
迭代式有些很好的动画,方便理解:修佬的笔记
斜堆
最大的区别:合并后无条件交换
摊还分析 :斜堆
- 势能函数:Φ(Heap)=number of heavy node in Heap
- 对于一个子堆 H,如果右子堆大小+1 ≥ 整个堆大小(左边+1是因为包括根节点) ,则 H 是heavy node,否则是light node。 摊还证明:
![[截屏2024-11-05 22.10.20.png]](/media/3.png)
![[截屏2024-11-05 22.18.49.png]](/media/4.png)
![[截屏2024-11-05 22.19.21.png]](/media/6.png) 至于为什么light nodes的数量是,课堂上已经证明过(可以预设light nodes最多的情况来作图,数学归纳法证明。
至于为什么light nodes的数量是,课堂上已经证明过(可以预设light nodes最多的情况来作图,数学归纳法证明。
- 对于一个子堆 H,如果右子堆大小+1 ≥ 整个堆大小(左边+1是因为包括根节点) ,则 H 是heavy node,否则是light node。 摊还证明:
习题
![[截屏2024-11-05 19.26.33.png]](/media/111.png) F
F
考点:skew heap, merge 操作, amortized cost计算, potential functions记忆
补充:左偏堆单点删除
(这个也忘记了,盘一下细节)
操作:只需要合并被删除的结点的两个子结点,得到新的树根节点去代替被删除的结点,再在回溯的过程中 bottom-up 地更新 dist 即可。
回溯maintain的过程:只要从新根节点开始检查/交换,因为左偏堆的子树都是左偏堆
代码实现:
LeftistHeapNode * del(LeftistHeapNode * cur, ElementType x) {
if (cur->val == x) {
return merge(cur->l, cur->r);
} else {
if (cur->val > x) return cur;//小根堆,找不到就返回cur指针
if (cur->l != NULL) del(cur->l, x);
if (cur->r != NULL) del(cur->r, x);
adjust(cur);//回溯操作
}
}
Divide && Conquer 时间复杂度计算(公式)
直接看修佬笔记
总结一下:
三类方法:代换法、递归树法、主方法
主方法形式三
考试一般会用到的是主方法第三种形式:![[截屏2024-11-05 22.28.18.png]](/media/7.png)
其他形式&方法的理解
- 代换法:先猜后证,证明时用放缩方法。
- 递归树法:等比数列求和;画出图
![[截屏2024-11-05 23.03.14.png]](/media/8.png)
- 可能需要运用数学工具:
![[截屏2024-11-05 23.04.28.png]](/media/9.png) (巧记:最上面和最下面换一下)
(巧记:最上面和最下面换一下)
- 可能需要运用数学工具:
- 主方法形式一(有人能记住吗)
![[截屏2024-11-05 23.11.11.png]](/media/10.png)
- 主方法形式二
![[截屏2024-11-05 23.11.29.png]](/media/11.png)
Binomial Tree && Binomial Queue
Binomial Tree
- 二项树是一个 N 叉树,所以通常我们使用链表 sibling 的形式来表示一个节点的 children。
- 性质:
![[1.png]](/media/123/1.png)
- 二项树满足堆的性质,即 parent 节点的值小于(大于) child 节点的值
- k 阶二项树都是同构的(k 阶二项树结构唯一确定),且 k 阶二项树是两个 k−1 阶二项树合并得到的。而其合并方式是直接令其中一棵成为另外一棵的根的新 child,因此二项树的每个 child 也是二项树。
- k阶二项树:
Binomial Queue:TBC
- 重要联系/工具:二进制表示
- N个节点,则有个二项树
- 操作
- 队列合并:从小到大合并(从低位到高位)。
- 查询队首:
![[ADS/media/123/2.png]](/media/123/2.png)
Precision && Recall 计算
![[ADS/media/123/3.png]](/media/123/3.png) precision:遍历(retrieved)到的 recall:相关(relevant)的 (为啥叫recall??)
precision:遍历(retrieved)到的 recall:相关(relevant)的 (为啥叫recall??)
B+树
参考我的平板笔记
红黑树
参考我的平板笔记
红黑树的操作动画:
Backtracking
Backtracing代码模板
可以类比八皇后和Turnpike Reconstruction的代码
bool Backtracking ( int i )
{ Found = false;
if ( i > N )
return true; /* solved with (x1, …, xN) */
for ( each xi Si ) {
/* check if satisfies the restriction R */
OK = Check((x1, …, xi) , R ); /* pruning */
if ( OK ) {
Count xi in;
Found = Backtracking( i+1 );
if ( !Found )
Undo( i ); /* recover to (x1, …, xi-1) */
}
if ( Found ) break;
}
return Found;
}
八皇后
代码实现:
#include<stdio.h>
#include<math.h>
#define bool int
#define false 0
#define true 1
bool Backtracking(int i, int a[], int N);
bool Check(int i, int j, int a[]);
int num;
int main(void){
int N;
scanf("%d",&N);
int a[N];
for(int cnt = 0; cnt < N; ++cnt)a[cnt] = 0;
bool tmp = Backtracking(1, a, N);
printf("%d\n", num);
return 0;
}
bool Check(int i, int j, int a[]){
for(int ci = 0; ci < i-1; ++ci){
if(a[ci] == j){
return false;
}
if(abs(a[ci] - j) == abs(ci + 1 - i)){
return false;
}
}
return true;
}
bool Backtracking ( int i, int a[], int N )
{ bool Found = false;
if ( i > N ){
if(num < 3){
for(int cnt = 0; cnt < N-1; ++cnt)printf("%d ",a[cnt]);
printf("%d\n",a[N-1]);
}
num++;
return true; /* solved with (x1, …, xN) */
}
for (int j = 1; j <= N; ++j) {
/* check if satisfies the restriction R */
int OK = Check(i, j, a); /* pruning */
if ( OK ) {
a[i-1] = j;
Found = Backtracking( i+1, a, N );
a[i-1] = 0;
}
}
return Found;
}
The Turnpike Reconstruction Problem 收费站问题
🔗修佬的笔记 ![[截屏2024-11-10 11.37.06.png]](/media/33.png) 代码实现:
代码实现:
bool Reconstruct ( DistType X[ ], DistSet D, int N, int left, int right )
{ /* X[1]...X[left-1] and X[right+1]...X[N] are solved */
bool Found = false;
if ( Is_Empty( D ) )
return true; /* solved */
D_max = Find_Max( D );
/* option 1:X[right] = D_max */
/* check if |D_max-X[i]|D is true for all X[i]’s that have been solved */
OK = Check( D_max, N, left, right ); /* pruning */
if ( OK ) { /* add X[right] and update D */
X[right] = D_max;
for ( i=1; i<left; i++ ) Delete( |X[right]-X[i]|, D);
for ( i=right+1; i<=N; i++ ) Delete( |X[right]-X[i]|, D);
Found = Reconstruct ( X, D, N, left, right-1 );
if ( !Found ) { /* if does not work, undo */
for ( i=1; i<left; i++ ) Insert( |X[right]-X[i]|, D);
for ( i=right+1; i<=N; i++ ) Insert( |X[right]-X[i]|, D);
}
}
/* finish checking option 1 */
if ( !Found ) { /* if option 1 does not work */
/* option 2: X[left] = X[N]-D_max */
OK = Check( X[N]-D_max, N, left, right );
if ( OK ) {
X[left] = X[N] – D_max;
for ( i=1; i<left; i++ ) Delete( |X[left]-X[i]|, D);
for ( i=right+1; i<=N; i++ ) Delete( |X[left]-X[i]|, D);
Found = Reconstruct (X, D, N, left+1, right );
if ( !Found ) {
for ( i=1; i<left; i++ ) Insert( |X[left]-X[i]|, D);
for ( i=right+1; i<=N; i++ ) Insert( |X[left]-X[i]|, D);
}
}
/* finish checking option 2 */
} /* finish checking all the options */
return Found;
}
ɑ-β 剪枝
参考【OI Wiki】alpha-beta 剪枝 应用案例:Tic-tac-toe
Tic-tac-toe: Minimax Strategy

 代码实现:
代码实现:
#include <stdio.h>
#define MAXN (8+1)
int n;
int ori_flag;
int leaves[MAXN]; // The value of each leaf, from left to right.
int max(int a, int b) { return a >= b ? a : b; }
int min(int a, int b) { return a <= b ? a : b; }
int dfs(int l, int r, int flag, int pruning_flag, int bound)
// `l` and `r` mark the two ends of the subscript of the leaves of the current subtree.
// `flag` marks whether current level returns the maximum (flag = 1) or minimum (flag = 0) value between the two children of the root.
// `pruning_flag` marks whether it is valid (pruning_flag = 1) to prune the right child of the root or not (pruning_flag = 0).
// `bound` is a bound of pruning.
{
int left_child, right_child;
//printf("%d %d\n", l, r); // Test which nodes are visited
if (l == r) return leaves[l]; // Base case for leaf nodes
left_child = dfs(l, l + (r - l) / 2, !flag, 0, bound);
// Pruning condition
if (pruning_flag && ((flag && left_child >= bound) || (!flag && left_child <= bound))) {
return left_child; // prune if condition met
}
right_child = dfs(l + (r - l) / 2 + 1, r, !flag, 1, left_child);
return flag ? max(left_child, right_child) : min(left_child, right_child);
}
int main()
{
scanf("%d%d", &n, &ori_flag);
for(int i = 1; i <= n; i++) { scanf("%d", &leaves[i]); }
printf("%d\n", dfs(1, n, ori_flag, 0, 0));
// When `ori_flag` is 1, the value of the root of the game tree is the maximum value between its two children,
// Otherwise the value of the root is the minimum value between its two children.
}
数据结构操作的时间复杂度汇总:需要勘误 TBC
已学数据结构的基本操作时间复杂度如下:(区分“是”“平均”“均摊(摊销)”的代价)
- AVL Tree (平衡操作时间复杂度是)
- 查找:
- 插入:
- 删除:
- Binary Search Tree (BST)
- 查找: 平均 ,最坏 (当树退化为链表时)
- 插入: 平均 ,最坏
- 删除: 平均 ,最坏
- Splay Tree
- 查找: 平均摊销 ,最坏
- 插入: 平均摊销 ,最坏
- 删除: 平均摊销 ,最坏
- B+ Tree
- 查找: —— B+树是一种多路平衡树,深度为 。
- 插入: —— 插入时可能分裂节点,但深度仍保持为 。
- 删除: ——删除时可能合并节点,复杂度为
- Binomial Queue
- 查找最小值:
- 插入: 单次是 (最坏);连续n次总共是,平均代价
- 删除最小值:
- 合并:
- Skew Heap
- 查找最小值:
- 插入: 摊销
- 删除最小值: 摊销
- 合并:
- Leftist Heap
- 查找最小值:
- 插入:
- 删除最小值:
- 合并:
看PPT
TO DO
- AVL, Splay Tree
- RB Tree, B+ Tree
- Heaps
- Inverted File Index
- Binomial Queue
- Backtracking
- Divide and Conquer
- DP
- Greedy Algorithms
Inverted File Index
这部分最好看:修佬的笔记
- Posting List 倒排列表 / 倒排表
- Term-Document Incidence Matrix 术语-文档关联矩阵
- Inverted File Index 倒排索引 几个搜索solution:
- solution 2: Term-Document Incidence Matrix
![[51.png]](/media/51.png)
- solution 3: Inverted File Index
- version 1:
![[52.png]](/media/52.png)
- version 2:
![[53.png]](/media/53.png)
- version 1:
Index Generator 伪代码
![[54.png]](/media/54.png) 内存不足时改进:
内存不足时改进: ![[56.png]](/media/56.png)
优化:reading a term
Word Stemming 词干分析
将单词转换为其词干,多个单词共享同一条索引记录,在存和找的过程中都能优化效果。
Stop Words
常用单词/字符不储存
优化:accessing a term
Search trees ( B- trees, B+ trees, Tries, … )
Hashing
利弊:
![[55.png]](/media/55.png)
Distributed indexing
Each node contains index of a subset of collection
有两种分布式的策略,其一是根据单词的字典序进行分布式,其二是根据文档进行分布。
显然根据单词的内容进行分布式,能够提高索引效率,但是这样的话,我们就需要将所有形式接近的单词都存储在一个地方,这样就会造成单点故障,容灾能力很差,所以这种方式并不是很好。
而第二种办法则有较强的容灾性能。即使一台机器无法工作,也不会剧烈影响到整个系统。 ![[57.png]](/media/57.png)
修佬笔记没有的内容:(PPT)
precision && recall的关系和理想情况图
![[58.png]](/media/58.png)
Dynamic indexing
新建doc、删除doc的操作![[59.png]](/media/59.png) 有许多不同的情况,问gpt
有许多不同的情况,问gpt
Compression
块级压缩(Blocking / Skip Pointers):
将posting list分成多个块,对每个块的起始位置建立指针。这样在检索时可以快速跳过不需要的部分,降低访问成本。 ![[60.png]](/media/60.png)
Thresholding 阈值转换法
本质上是讨论文档的哪些部分需要搜索,减少搜索范围。 ![[61.png]](/media/61.png) (图示第二种)查询: 按频率升序排列查询词;仅根据原始查询词的部分百分比进行搜索。
(图示第二种)查询: 按频率升序排列查询词;仅根据原始查询词的部分百分比进行搜索。
Binomial Queue
![[63.png]](/media/63.png) 注意binomial queue的插入代价有两种,一种是单次,一种是连续n次,两者不一样。
注意binomial queue的插入代价有两种,一种是单次,一种是连续n次,两者不一样。 ![[64.png]](/media/64.png)
![[65.png]](/media/65.png) ↑需要记忆
↑需要记忆
解释:第三步为什么是:需要把每个子树都摘下来塞进新的binomial queue,所以最多遍历个子树根节点。
![[66.png]](/media/66.png)
![[68.png]](/media/68.png)
![[70.png]](/media/70.png) 代码需要记忆
代码需要记忆
这种操作的时间复杂度为
combine里的交换,目的是搭建小根堆(元素小的作为新树根节点,大的作为新根节点的新左儿子)
merge 操作代码: ![[71.png]](/media/71.png) 这个代码考过作业填空。要注意switch括号里的顺序!
这个代码考过作业填空。要注意switch括号里的顺序!
我们为了节省空间,习惯把merge后的结果储存在两个queue数组的其一中(这里是结构体数组H1)
111的情况,不同题目的考虑可能不一样,T1,T2,Carry都有可能成为当前位的子树
不要忘记对CurrentSize的更新!
DeleteMin操作实现: ![[72.png]](/media/72.png) 不要忘记:
不要忘记:
- 两个binomial queue的CurrentSize的更新
- free替换后的旧指针
- NextSibling置为NULL,断开
MaxTrees的值可以被替换为实际根的数量。
binomial queue连续n次插入的代价证明:摊还分析 ![[73.png]](/media/73.png)
![[74.png]](/media/74.png)
- splay trees:势能函数是所有子树大小的对数和(具体怎么推?)
- skew heaps:heavy nodes的数目,但是只要看最右侧路径的heavy nodes变化(这里有较多结论)
- binomial queues:二进制,看1的数目为势能
Heap
![[75.png]](/media/75.png)
![[76.png]](/media/76.png) 左偏堆节点定义:
左偏堆节点定义:![[77.png]](/media/77.png) 比普通BST额外维护了Npl,这也是后面斜堆优化的对象
比普通BST额外维护了Npl,这也是后面斜堆优化的对象
merge操作:
三步走:merge, attach, swap ![[78.png]](/media/78.png) 时间复杂度为,因为树的高度为
时间复杂度为,因为树的高度为
不要忘记更新Npl(交换后相当于是RightChildren的npl +1)
![[79.png]](/media/79.png) iterative是先对各个右子树根sort然后不断连接右儿子。最后还要从下至上进行判断和swap
iterative是先对各个右子树根sort然后不断连接右儿子。最后还要从下至上进行判断和swap
DeleteMin同理也可以证明是时间复杂度
![[80.png]](/media/80.png)
![[96.png]](/media/96.png) 这里的最后一个被合并右子树(根节点)为18,18不需要再swap它的子树。
这里的最后一个被合并右子树(根节点)为18,18不需要再swap它的子树。
insert同样也是特殊的merge ![[81.png]](/media/81.png) 这里的iterative不同于左偏堆,每回合合并的右子树节点都接在左儿子指针,然后无条件交换自己的子树。注意这里还是最后一个右子树节点不需要swap。
这里的iterative不同于左偏堆,每回合合并的右子树节点都接在左儿子指针,然后无条件交换自己的子树。注意这里还是最后一个右子树节点不需要swap。
摊还分析前面写了,这里就不提了。
RB Tree && B+ Tree
1. RB Tree
![[82.png]](/media/82.png) 性质:黑根,黑叶子结点,不红红,黑路同
性质:黑根,黑叶子结点,不红红,黑路同
![[83.png]](/media/83.png)
![[84.png]](/media/84.png)
黑高不包括x节点自身,也不包括NIL ![[85.png]](/media/85.png)
![[86.png]](/media/86.png)
![[87.png]](/media/87.png) 红黑树插入:
红黑树插入:
默认插入节点为红色,分为三种情况: ![[92.png]](/media/92.png) 其中第一种违反根叶黑,第二、三种违反不红红。其他情况不违背,不需要考虑调整。
其中第一种违反根叶黑,第二、三种违反不红红。其他情况不违背,不需要考虑调整。
分析第二、三种情况:
- 父节点肯定是红色的。
- 叔叔是红色,那么祖父节点肯定是黑色 -> 祖父和叔父辈交换颜色,这时祖父节点可能也违反了性质,重新按照插入红节点的方法处理
- 叔叔是黑色,这种情况叔叔肯定是NIL,祖父节点是红色,只有一个子节点为父节点。那么需要旋转,然后父节点变黑,原先祖父节点为根的这个子树结构仍然保持黑高不变,不需要做其他部分的调整 红黑树删除:
考虑BST性质,删除三种情况: ![[93.png]](/media/93.png) 那么前两种情况,进一步考虑红黑树性质的影响:
那么前两种情况,进一步考虑红黑树性质的影响:
- 第二种情况,相当于只有一个孩子,必然是叶子结点为红,父节点为黑 -> 直接删除没有影响
- 第一种情况,没有孩子:
- 如果删除的是红节点,不会影响黑高,直接删。
- 如果删除的是黑节点,去查表,理解为什么这么操作(…………)
2. B+ Tree
![[88.png]](/media/88.png)
![[89.png]](/media/89.png) 关于叶子节点分裂:
关于叶子节点分裂: ![[90.png]](/media/90.png)
![[截屏2024-11-13 00.03.51.png]](/media/91.png) 这里没消化完
这里没消化完
Backtracing
八皇后限制: ![[94.png]](/media/94.png) 第一个限制加上第二个限制,解的可能性从变为
第一个限制加上第二个限制,解的可能性从变为 ![[95.png]](/media/95.png) 八皇后时间复杂度(加上剪枝)为, 剪枝前是单纯的暴搜回溯,时间复杂度为
八皇后时间复杂度(加上剪枝)为, 剪枝前是单纯的暴搜回溯,时间复杂度为
收费站重建问题:
- 最优时间复杂度是,其中递归调用次,每次调用开销为
- 最坏时间复杂度是,其中递归调用次,每次调用开销为
Divide && Conquer
![[97.png]](/media/97.png) ↑递归树法结合先猜后证法的一个例子(递推式不止一个情况)
↑递归树法结合先猜后证法的一个例子(递推式不止一个情况)
画出分治树后猜证,其实中间也带了放缩思想
![[98.png]](/media/98.png) 常规(一项)的还是等比数列求和,也要画出图
常规(一项)的还是等比数列求和,也要画出图
Dynamic Programing
0. 基本概念 && 方法
斐波那契数列: ![[101.png]](/media/101.png) ↑DP优势的本质:存储、调用过去子问题的解,避免重复计算。用少量的空间存储代价换计算时间代价。
↑DP优势的本质:存储、调用过去子问题的解,避免重复计算。用少量的空间存储代价换计算时间代价。
DP问题的要素:当前问题的最优解包含子问题的最优解(可以通过举反例思考是不是这样) ![[103.png]](/media/103.png)
![[106.png]](/media/106.png)
DP程序五要素:
- DP数组含义
- 递推关系(状态转移)
- DP数组初始化
- DP数组遍历顺序
- 打印数组 其实有时候最难的反而是理解,而非代码实现。为了高效应对考试,我们采取熟悉基本模型和习题拓展的方法,并不做过多延伸。
然后关于五要素,我们要在具体题型案例中把握细节关键。 ![[102.png]](/media/102.png)
ps: 这才是真正的动规(x): ![[100.png]](/media/100.png)
↑DP问题的思考模型,good
1. Product Assembly 问题
![[104.png]](/media/104.png)
![[105.png]](/media/105.png) 代码:(如果只要求最小值,版本1就够了)
代码:(如果只要求最小值,版本1就够了)
- 版本1
![[115.png]](/media/115.png)
- 版本2
![[107.png]](/media/107.png)
![[108.png]](/media/108.png)
2. Ordering Matrix Multiplications 问题
![[109.png]](/media/109.png) 得到递推式:
得到递推式: ![[110.png]](/media/110.png) 递归方程:
递归方程: ![[112.png]](/media/112.png) 代码实现:
代码实现: ![[114.png]](/media/113.png)
![[113.png]](/media/114.png) 同理,如果要使程序能够回溯矩阵乘最优顺序,那么需要S数组来记录过程:
同理,如果要使程序能够回溯矩阵乘最优顺序,那么需要S数组来记录过程: ![[117.png]](/media/117.png)
3. Optimal Binary Search Tree (OBST)
![[116.png]](/media/116.png) 根据k的编号确定是哪个word作为当前树根
根据k的编号确定是哪个word作为当前树根
↓通过两张表,查表构建得到OBST: ![[118.png]](/media/118.png) 这个应该只需要知道算法,不需要知道代码?
这个应该只需要知道算法,不需要知道代码?
算法(补充):wyy的讲义: ![[119.png]](/media/119.png)
4. All-Pairs Shortest Path
![[120.png]](/media/120.png) method 1适用于稀疏图,时间复杂度为;method 2适用于密集图,时间复杂度为
method 1适用于稀疏图,时间复杂度为;method 2适用于密集图,时间复杂度为
method 2看前k项来递归
算法考虑的是k是否在最短路径中: ![[121.png]](/media/121.png) 代码实现:
代码实现: ![[122.png]](/media/122.png) 要注意在循环中的遍历顺序!
要注意在循环中的遍历顺序!
其实感觉第三层(j的循环)可以从i+1开始。
Greedy Algorithm
- 最优解定义:A feasible solution for which the function has the best possible value
- 贪心策略定义:Make decisions in stages. Find a best choice at each stage, under some greedy criterion, without violating the whole “feasibility”(keys: 阶段,贪心准则,最优选择)
1. The Activity Selection Problem
每次选择最早结束的活动意味着我们“耗费”的时间最少,最大限度地增加后续活动的安排可能性。
该算法时间复杂度为,其中排序,选择活动。
判断为最优贪心解:
- 局部贪心(剩余时间最多)
- 全局最优解(消耗的时间最少)
- 满足题意,不冲突
![[124.png]](/media/124.png)
![[125.png]](/media/125.png)
2. Huffman Codes
复习过,略。